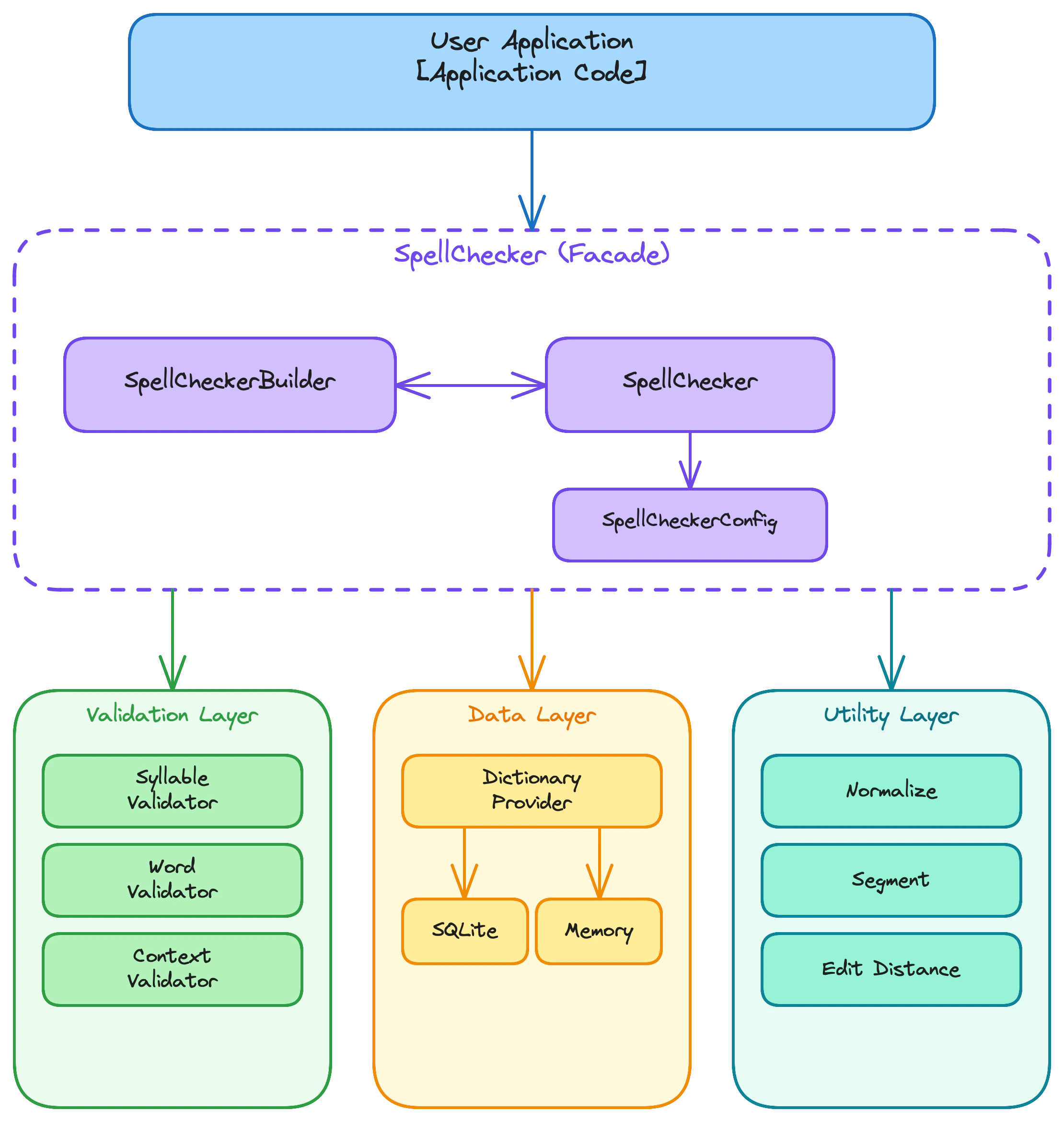
High-Level Architecture
Validation Layer Components
SyllableValidator
SyllableRuleValidator
Structure rules
Medial order
Vowel compatibility
Dictionary Lookup
Syllable exists?
Frequency lookup
WordValidator
Dictionary Lookup
Word exists?
Get frequency
Get POS
SymSpell Algorithm
Generate deletes
Find suggestions
Rank by distance
ContextValidator (Strategy-based)
SyntacticValidationStrategy (Layer 2.5)
POS Tagger
Viterbi HMM
Transformer
Rule-based
SyntacticRuleChecker
Particle rules
Sequence rules
Linguistic rules
N-gram Checker
Bigram probs
Trigram probs
Smoothing
Semantic Checker (Optional)
ONNX model
Embedding lookup
SpellChecker Mixin Architecture
SpellChecker uses a mixin-based decomposition to organize detection and suggestion logic into focused modules while preserving a single public API surface:
SpellChecker (core/spellchecker.py)
PreNormalizationDetectorsMixin
11 pre-normalization detectors
Run before text normalization
PostNormalizationDetectorsMixin
38 ordered detectors (via detection_registry.py)
Particle confusion, medial confusion, compound typos, etc.
SentenceDetectorsMixin
10 sentence-level detectors
Register mixing, tense mismatch, structure issues
SuggestionPipelineMixin
24 suggestion/reranking methods
Unified ranking across sources
ErrorSuppressionMixin
21 suppression/dedup/merge methods
Prevents duplicate errors at same position
Detection Registry
The post-normalization detection pipeline is controlled by an ordered registry incore/detection_registry.py. Each entry maps to a _detect_* method inherited from detector mixins:
broken_stacking must run before colloquial_contractions to prevent stacking errors from being claimed as colloquial variants.
Data Layer Components
DictionaryProvider defines the abstract interface:
is_valid_syllable(syllable)→boolis_valid_word(word)→boolget_word_frequency(word)→intget_bigram_probability(prev, curr)→float
DictionaryProvider (Abstract)
SQLiteProvider (disk-based, indexed, default)
MemoryProvider (RAM-based, fast, high mem)
JSONProvider (testing, simple)
CSVProvider (testing, simple)
Algorithm Components
Data Pipeline Components
Component Interactions
Check Operation Flow
See Data Flow for detailed check operation flow.Suggestion Generation Flow
Dependency Graph
SpellChecker
SyllableValidator → DictionaryProvider
WordValidator → DictionaryProvider
SymSpell → DictionaryProvider
ContextValidator → DictionaryProvider
SQLiteProvider (default)
MemoryProvider (alternative)
See Also
- Architecture Overview - High-level architecture
- Data Flow - Data flow diagrams
- Extension Points - Customization guide