Quick Start
Build a dictionary from the command line:Pipeline Architecture
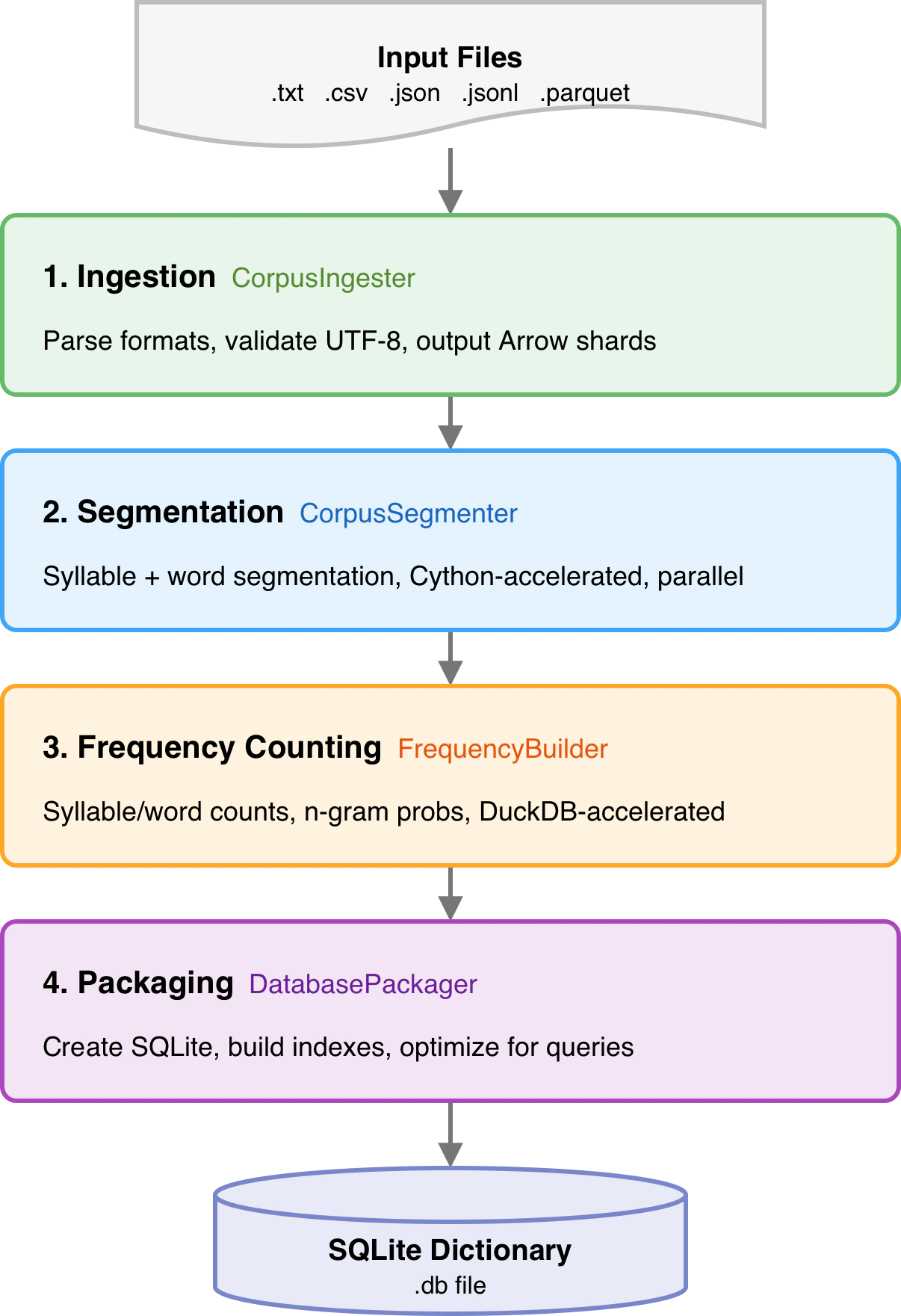
What the Database Contains
| Table | Content | Purpose |
|---|---|---|
syllables | Valid syllables + frequencies | Syllable validation |
words | Words + frequencies + POS tags | Word validation, suggestions |
bigrams | Word pair probabilities | Context checking (2-gram) |
trigrams | Word triple probabilities | Context checking (3-gram) |
fourgrams | 4-word sequence probabilities | Context checking (4-gram) |
fivegrams | 5-word sequence probabilities | Context checking (5-gram) |
pos_unigrams/bigrams/trigrams | POS tag probabilities | Grammar checking |
metadata | Key-value build metadata | Build info, versioning |
processed_files | Ingested file paths + timestamps | Incremental updates |
confusable_pairs | Confusable word pairs + type + overlap | Confusable error detection |
compound_confusions | Compound vs split-word pairs + PMI | Compound error detection |
collocations | Word pair co-occurrence + PMI/NPMI | Collocation error detection |
register_tags | Word register labels (formal/informal) | Register mixing detection |
Next Steps
Corpus Format
Supported input formats and requirements
Building Dictionaries
CLI reference, Python API, config options
Optimization
DuckDB acceleration, Cython, parallel workers
Custom Dictionaries
Curated lexicons, domain-specific builds